0. 主从复制机制
binlog
如何评价redis的高性能?为何要把Redis设计成单线程?
(1)redis全内存,单线程,无锁。
(2)redis Rehash 渐进式hash,双缓冲 + 分而治之思想
关于写入,仅写ht[1],不再写入ht[0];关于读取,优先读ht[1], 没有的话,再读取ht[0]
渐进式迁移的过程中,一次迁移一个bucket。包括用于解决冲突的hash链。
以下是哈希表渐进式 rehash 的详细步骤:
(1)为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
(2)在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示 rehash 工作正式开始。
(3)在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1] , 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一。
(4)随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被 rehash 至 ht[1] , 这时程序将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
INT 64 位有符号整数类型的时候将会采用 INT 编码。 值在[0,1000)之间。 如果存入整数的值在[0,1000)中Redis将不会创建新的对象,而是直接指向共享对象,键值不额外占用空间。
EMBSTR(EmbeddedString, 当存储的字符串长度较短时(len<=44 字节),Redis将会采用 embstr 编码,避免再次分配内存, 复用redis object)。这个长度是咋计算出来的呢? 跟redis的底层内存池(jcmalloc)有关系。 64字节减去一些元数据。
RAW 原始字符串
ZIPLIST (压缩列表,连续内存,内存利用率高,增删改查效率低下;当hash、zset、list元素少且内容不大时使用该编码),
压缩列表是一块连续的内存空间,元素之间紧挨着存储,没有任何冗余空隙。每次有写操作的时候,会重新分配内存,例如insert, remove等操作。
QUICK_LIST(list元素较多时使用)
double list of ziplist
quicklist 实际上是 zipList 和 linkedList 的混合体,它将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。
INTSET(整数集合,当set元素较少且都为整数时,使用该编码,从小到大的顺序存储,方便做交、并、差集运算。
intset是一个由整数组成的有序集合,从而便于在上面进行二分查找,用于快速地判断一个元素是否属于这个集合
ziplist可以存储任意二进制串,而intset只能存储整数。
ziplist是无序的,而intset是从小到大有序的。因此,在ziplist上查找只能遍历,而在intset上可以进行二分查找,性能更高。
ziplist可以对每个数据项进行不同的变长编码(每个数据项前面都有数据长度字段len),而intset只能整体使用一个统一的编码(encoding)。
HASH(hash元素较多时使用) 渐进式扩容缩容策略
SKIPLIST(跳表,zset元素多时使用)
| 数据结构 | 紧凑实现 | 大致实现 |
|---|---|---|
| string | INT(仅限long类型的string), EMBSTR(字符串比较短,44以内) | RAW(普通字符串) |
| hash | ZIPLIST(元素较少,成员较小) | HASH |
| zset | ZIPLIST(元素较少,成员较小) | SKIPLIST + Dict |
| set | INTSET(集合元素不多, 且元素可以表示为int) | HASH |
| list | ZIPLIST(元素较少,成员较小) | QUICK_LIST |
实际上,Redis中sorted set的实现是这样的:
当数据较少时,sorted set是由一个ziplist来实现的。
当数据多的时候,sorted set是由一个dict + 一个skiplist来实现的。简单来讲,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
score字段是数据对应的分数。
backward字段是指向链表前一个节点的指针(前向指针)。节点只有1个前向指针,所以只有第1层链表是一个双向链表。
level[]存放指向各层链表后一个节点的指针(后向指针)。每层对应1个后向指针,用forward字段表示。另外,每个后向指针还对应了一个span值,它表示当前的指针跨越了多少个节点。span用于计算元素排名(rank),这正是前面我们提到的Redis对于skiplist所做的一个扩展。需要注意的是,level[]是一个柔性数组(flexible array member),因此它占用的内存不在zskiplistNode结构里面,而需要插入节点的时候单独为它分配。也正因为如此,skiplist的每个节点所包含的指针数目才是不固定的,我们前面分析过的结论——skiplist每个节点包含的指针数目平均为1/(1-p)——才能有意义。
假设我们在这个skiplist中查找score=89.0的元素(即Bob的成绩数据),在查找路径中,我们会跨域图中标红的指针,这些指针上面的span值累加起来,就得到了Bob的排名(2+2+1)-1=4(减1是因为rank值以0起始)。需要注意这里算的是从小到大的排名,而如果要算从大到小的排名,只需要用skiplist长度减去查找路径上的span累加值,即6-(2+2+1)=1。
可见,在查找skiplist的过程中,通过累加span值的方式,我们就能很容易算出排名。相反,如果指定排名来查找数据(类似zrange和zrevrange那样),也可以不断累加span并时刻保持累加值不超过指定的排名,通过这种方式就能得到一条O(log n)的查找路径。
skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
从算法实现难度上来比较,skiplist比平衡树要简单得多。
redis是如何实现可靠存储的:真的可靠吗? AOF、RDB有啥区别? 分别适用于什么场景?
借助AOF、RDB可以一定程度上减少数据的损失,但是都无法做到数据的100%。
RDB,定期fork一个子进程,通过copy on write技术,来进行内存的dump,成本相对AOF较高,所以不可能很短时间内就dump一次,所以如果内存中的数据还没有来得及dump到RDB,那么会丢失比较多的数据,好处是借助RDB恢复数据比较快。 RDB最大的时间成本是clone页表。
AOF,定期(通常是s级别)append 写操作命令到文件中,只是简单的写一次磁盘,所以性能较好,如果新的命令append到aof之间发生宕机,丢失的数据也比较少。缺点是每次基于AOF恢复数据会比较慢。
AOF缓冲数据的写入策略:NO(依赖操作系统的flush盘机制)、always(性能最差,安全性最好)、everySecond(最多丢失1~2秒数据)
AOF重写【BGREWRITEAOF】,AOF 重写缓冲区
目的是为了减少AOF文件的大小,会有重复写同一个K的多条命令,从而造成常规AOF过大。
把主线程的内存拷贝一份给fork出来的 bgrewriteaof 子进程,这里面包含了Redis中最新的数据。

下表是完整的AOF后台重写过程:
时间 服务器进程(父进程) 子进程
T1 执行命令 SET K1 V1
T2 执行命令 SET K1 V1
T3 执行命令 SET K1 V1
T4 创建子进程,执行AOF文件重写 开始AOF重写
T5 执行命令 SET K2 V2 执行重写
T6 执行命令 SET K3 V3 执行重写
T7 执行命令 SET K4 V4 完成AOF重写,向父进程发送信号
T8 接收到信号,将T5 T6 T7 服务器的写命令追加到新的AOF文件末尾
T9 用新的AOF替换旧的AOF
T8 T9执行的任务会阻塞服务器处理命令。
https://www.51cto.com/article/694868.html
Redis 3.0 基于checkpoint思想的新持久化方式
redis tw代理模式与cluster集群模式分别是如何工作的? 哪一种模式使用了一致性Hash?
两者都是为了解决单机数据存不下的问题。数据存不下,只能通过多台来存。
客户端通过tw代理模式访问redis集群,数据分片使用了一致性hash,以尽可能减少某台redis机器不可用造成的影响,但是还是会丢数据。
官方的cluster集群方案是由客户端sdk来维护slot分布,数据分片分片是通过CRC16(key)%16834来实现。无中心化,node之间通过gossip协议来进行通信,选主等。
另外,redis cluster还尝试解决高可用的问题,但是由于CAP理论,他选择了可用性,丢失了一致性。 丢失一致性的点在于:1)异步复制;2)网络分区。
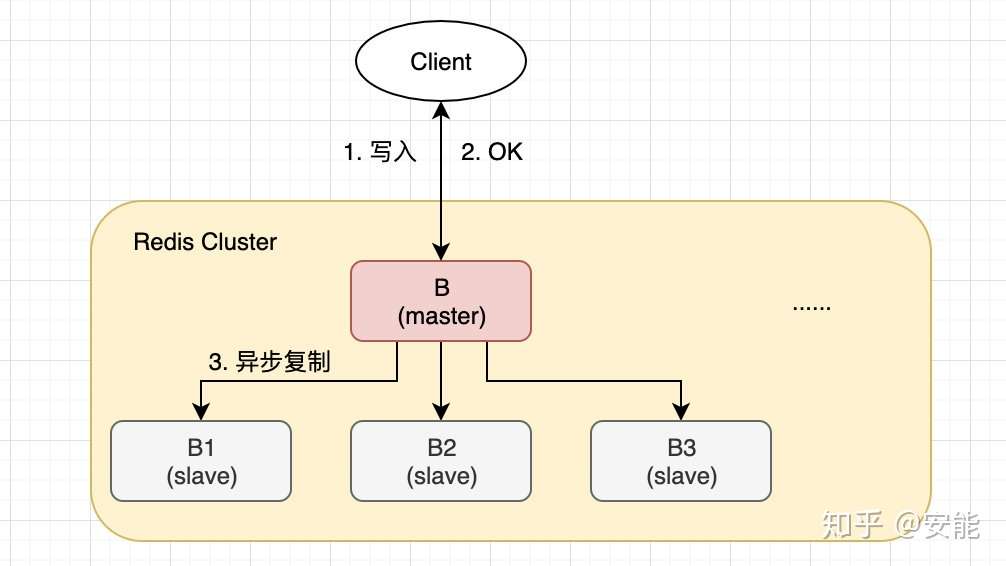
另外值得一提的是Redis哨兵模式。这种模式只能解决高可用的问题(并不能保证数据不丢失),但是无法解决数据太大的问题。
分布式锁的特性:排他性、无死锁、高可用。
先说加锁,setnx命令,支持cas操作,并且支持设置超时时间。通过设置超时时间这个功能点,可以避免加锁后进程挂掉造成的锁没法释放的问题。
但是这种加锁方案还有一个缺点,那就是超时时间很难设置的很合理,设置过短可能会引起加锁时间内不足以完成业务逻辑;设置过长又导致宕机恢复时间过长。
这种情况下,我们可以额外启动一个WATCH-dog线程来监视这些锁,如果锁快要到期了,就调用expire命令对锁进行续期;业务完成时禁用watch-dog即可。
再说解锁unlock,理想情况下,解锁时只要通过del命令来把锁定的key删除即可。但是实际情况可能会更复杂一些。
第一个问题,如果删除的key不是加的锁怎么办? 容易想到,加锁时,设置key的value为一个unique id。 解锁删除时,先get一下key,看看key对应的value是不是跟预期的id相符,如果相符,del;否则,noop,说明我正准备删除别人加的锁。
但是刚才的方案,还有一个缺陷那就是get跟del两个操作不是一个原子的,中途可能会被打断。如果真的被打断,还是会出现误解锁的过程。此时我们可以借助lua脚本将刚才的两个步骤原子化。至此,解锁操作才算基本完成。
上面的方案还有啥问题呢? 如果主从同步未完成,而主挂掉了,从节点上位之后,会导致之前加的锁失效。 这个问题,官方给的解决方案是使用redis cluster的红锁来解决。
最后再提一下,除了redis可以实现分布式锁,还可以通过mysql数据库(version乐观锁,for update悲观锁),zookeeper等来实现分布式锁。
惰性淘汰:在key请求时,判断key是否失效,失效就淘汰
定时策略:每隔100毫秒检测一次, 移除所有已过期的键
如果发现超过25%的键过期,会重复执行。
当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行。
2个维度的组合:
最多一共有$3^3$种组合,只是有一些没有意义。例如空集 + LRU、所有的 + 最短TTL。 剩下的有意义的包括:
volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间 存放。
事务,但 Redis 提供的不是严格的事务,Redis 只保证串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去。
watch 一个变量, multi exec 根据中间有没有其他线程更改watched的变量来决定,是commit事务还是rollback事务,有点像CAS操作,只是Redis的watch机制并没有ABA问题
Bitmap :
位图是支持按 bit 位来存储信息,可以用来实现 布隆过滤器(BloomFilter);
HyperLogLog:
供不精确的去重计数功能,比较适合用来做大规模数据的去重统计,例如统计 UV;
实现原理:基于概率的hash数据结构,基于N次伯努利实验。具体参考:基数统计
Geospatial:
可以用来保存地理位置,并作位置距离计算或者根据半径计算位置等。有没有想过用Redis来实现附近的人?或者计算最优地图路径?
巧妙的GEOhash,将范围查询转换为更加有效的点查询。
https://blog.csdn.net/usher_ou/article/details/122716877
这三个其实也可以算作一种数据结构,不知道还有多少朋友记得,我在梦开始的地方,Redis基础中提到过,你如果只知道五种基础类型那只能拿60分,如果你能讲出高级用法,那就觉得你有点东西。
pub/sub:
功能是订阅发布功能,可以用作简单的消息队列。
Pipeline:
可以批量执行一组指令,一次性返回全部结果,可以减少频繁的请求应答。
Lua:
Redis 支持提交 Lua 脚本来执行一系列的功能。
我在前电商老东家的时候,秒杀场景经常使用这个东西,讲道理有点香,利用他的原子性。
1 |
|
参考这篇文章写的比较全面
https://zhuanlan.zhihu.com/p/521265336
先说最重要的数据库、缓存一致性问题,关于该问题,有以下几点需要考虑:
当DB数据发生变更时,是删除缓存还是修改缓存?
答案是删除缓存。相比修改缓存,删除缓存是幂等性操作。删除缓存可以避免出现双写并发问题。
另外一点,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值,也就是说update的value是什么我无法简单得知。
懒加载思想: 更新了,但是没有读请求就白白浪费内存了。
先写DB还是先写缓存?
答案是先操作DB。结合case1, 在读多写少的高并发场景下,如果先删缓存再操作DB,有一个很明显的逻辑错误,使得有极高的概率出现读写并发问题。虽然先db后缓存的方式也无法完全避免这类问题,但是出现的概率极低。【详细的问题时序见下文】
出现并发问题的时序如下:
高并发下,关于缓存的一致性会出现什么问题?
case1, case2中提到了在高并发的情况下,会出现某种并发逻辑错误,导致数据不一致。
是否听说过订阅数据库binlog变更去清理缓存的方法?这个方法的使用场景是啥?
通过binlog变更的方式去清理缓存,有两个好处:第一,无业务侵入型;第二,支持无限重试。
CacheAside模式,一定是最佳的吗?不一定,具体场景具体分析:
(1)新用户注册场景,同时数据库主从延迟1s
解决方案:新建数据库 + 新建缓存(避免读取到延迟的数据结果)
Cache Aside 策略是我们日常开发中最经常使用的缓存策略,不过我们在使用时也要学会依情况而变,并不是一成不变的。Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果你的业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
(2)写入特别频繁的场景,而我们对命中率有一定的要求
解决方案:
两种应对write miss的办法:
(1)write-allocate 写cache,再由cache更新db
(2)no write allocate 直接更新db
这个策略的核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。


变种:在允许数据丢失的情况下,写入时只写缓存,而异步写入存储。
再说缓存穿透问题。
首先明确什么是缓存穿透问题?考虑在很高的读并发下,如果某一个redis key突然过期,会发生什么?如果真的发生这种情况,并且我们没有任何预防措施,按照cache aside模式,程序会read from db,然后set cache。但是由于并发很高,所有的线程同时去请求db,造成db过载不可用。我们称这种现象就缓存穿透。通过分布式锁来控制仅一个线程去read db,而其他线程等待,可以一定程度上避免缓存穿透问题。
缓存并发穿透(狗桩效应):极热点缓存失效,大量请求穿透到DB,造成DB瞬时压力过大
如何解决缓存并发穿透呢?
(1)热点发现,定时续期
(2)对于极热点,启用本地缓存
还有一种情况,如果请求的某一个key在db中也不存在,我们需要设置一个拥有较短TTL的空缓存来避免每次请求都穿透到db。
回种空值—-缺点在于:会占用很大的内存来存储好多无用请求,需要评估内存是否OK
布隆过滤器—-在写入DB时,额外写一份数据到布隆过滤器,查询时优先访问过滤器

最后谈一下缓存雪崩。
同样先搞清楚什么是缓存雪崩。由于某些系统设计不合理,缓存会设置为相同的过期时间或者很接近。这样子在某个时间点,缓存便会近乎同时失效,造成业务请求全部回源db,造成db过载,我们称这种情况为缓存雪崩。一般情况下,我们需要有意的设置key的过期时间,让他们随机过期,从而解决缓存同时过期导致的缓存雪崩问题。
高并发多线程的情况下,热Key重键是使用redis比较典型的一个问题:
解决方案:
在用途方面,他们有各自默认的用途:
寄存器ESI、EDI、SI和DI称为变址寄存器(Index Register),
它们主要用于存放存储单元在段内的偏移量,用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。
那么ESP和EBP指的分别是什么呢?
对于64位CPU,EAX —-> RAX
段寄存器
段寄存器包含index、LDT/GDT、PL
CS 代码段
DS 数据段
SS 堆栈段
ES 附加段
IP寄存器是干嘛用的?
CS:IP 对应着指令地址,分别对应.text段以及段内offset;IP对程序不可见,由CPU自己管理
可执行程序的逻辑分段
.text段 【占程序大小】<==> CS代码段, 只读可执行
.data段 【占程序大小】<==> DS代码段, 可读可写
.bss段 【不占程序大小,仅需要长度,初始化为0】<==> DS代码段, 可读可写
.heap 【不占大小】<==> SS代码段
.stack 【不占大小】<==> SS代码段
段描述符寄存器,存放段描述符的,对程序不可见,供CPU使用。
GDT 全局(段)描述符表,是一个一位数组,数组size为一共有多少个段,数组Item为:
段描述符,描述了段的base、段的size、段的权限等;
LDT
关于为什么LDT要放在GDT中
LDT中的描述符和GDT中的描述符除了选择子的bit3一个为0一个为1用于区分该描述符是在GDT中还是在LDT中外,描述符本身的结构完全一样。开始我考虑既然是这样,为什么要将LDT放在GDT中而不是像GDT那样找一个GDTR寄存器呢?
后来终于明白了原因——很简单,GDT表只有一个,是固定的;而LDT表每个任务就可以有一个,因此有多个,并且由于任务的个数在不断变化其数量也在不断变化。如果只有一个LDTR寄存器显然不能满足多个LDT的要求。因此INTEL的做法是把它放在放在GDT中。
GDTR,GDTR是一个长度为48bit的寄存器,内容为一个32位的基地址和一个16位的段限。其中32位的基址是指GDT在内存中的地址。存储了GDT的地址。
LDTR,LDTR是局部段描述符寄存器,由一个可见的16位寄存器(段选择子)和一个不可见的段描述符寄存器组成(描述符寄存器实际上是一个不可见的高速缓冲区)。
系统任务切换时,LDT切换,而GDT不切换(因为真个系统只有一个GDT),这时新任务的LDT描述符的选择子就被装入到LDTR中。
GDTR和LDTR如何把虚拟地址转换线性地址
//TODO 需要进一步了解!
https://blog.csdn.net/wrx1721267632/article/details/52056910
GDTR是一个48位寄存器,指向全局描述符表GDT,从16位到47位前32位表示GDT在内存中的地址,是线性地址,需要通过页表转换成物理地址
LDTR是一个16位寄存器,是在GDT中的索引,指向局部描述符表LDT,每个任务有一个LDT,不同的LDT占用不同的内存段,由不同的系统描述符描述,这些系统描述符放在GDT中.
LDTR里面保存的是索引值,指向LDT在GDT中的位置
如果手头上有虚拟地址xxxx:yyyyyyyy
首先从GDTR中取出GDT的基址BA找到GDT
xxxx一共16位,根据倒数第三位即T1位判断
如果T1=0,xxxx的前13位表示的是GDT的位置索引,根据索引得到一个描述符
该描述符含有段的基址与其他各种信息,段的起始地址+yyyyyyyyy就得到线程地址
如果T1=1,那么从LDTR得到LDT的位置索引,在GDT里面找到LDT描述符,LDT描述符里面包含LDT的线性地址
找到LDT,取出xxxx的前13位,在LDT中找到段描述符,该段描述符里面包含段的基址等信息.
而后段的基址加上yyyyyyyy得到线性地址
一个基本的CPU执行计算的过程如下:
栈的增长方向:向下增长,ESP越来愈小、ESP比EBP小

一个函数执行步骤:
所谓指令集,是CPU中用来计算和控制计算机系统的一套指令的集合。指令的强弱是CPU的重要指标,指令集是提高微处理器效率的最有效工具之一。
CPU依靠指令来计算和控制系统,每款CPU在设计时就规定了一系列与其硬件电路相配合的指令系统。与其他硬件电路相配合,决定的是这一款CPU的生态系统。因此,指令集搭建的是一个桥梁,是软硬件之间沟通的桥梁,简单来说,软件通过指令集和硬件讲话。因此,指令集对形成生态至关重要,从这个意义上讲,不同的CPU指令集,决定了这款CPU设计的复杂程度。
从现阶段的主流体系结构讲,指令集可分为复杂指令集(CISC, complex instruction set computer)和精简指令集(RISC, reduced instruction set computer)两部分。简单来讲,RISC功能简洁,代表着简洁的CPU设计,CISC功能完备,代表着复杂的CPU设计。
这里引用步日欣老师文章中的一段话:
CPU的指令,就如同盖房子的砖,如果都是小块的标准砖头,也能盖起各种不同的房子,这就是RISC;
如果除了标准砖头,还设计了很多的砖瓦结构件,适用于拐角、吊梁等,这就是CISC。
不同的模式,都能盖起房子,但是效率却大不一样,RISC的标准砖头,小平房可以盖,
摩天大楼也可以盖,底层的原材料很简单,都是标准化的砖头;
CISC的各种复杂的结构件,对于盖一种房子的时候效率确实高,吊起结构件随便一拼装就ok,
但是如果要盖的房子种类多了,就需要定义更多更复杂的结构件,结构件的管理就会越来越复杂,
而且在建设某种常见建筑的时候,大部分特殊的结构架是闲置不用的,大大影响了施工效率。
基于CISC模式下的CPU设计,在各种新需求下,堆叠的功能越来越复杂,芯片设计难度也越来越高,效率低下,
因此就出现了RISC精简指令集的概念。
CISC的指令能力强,单多数指令使用率低却增加了CPU的复杂度,指令是可变长格式;RISC的指令大部分为单周期指令,指令长度固定,操作寄存器,只有Load/Store操作内存
CISC支持多种寻址方式;RISC支持方式少
CISC通过微程序控制技术实现;RISC增加了通用寄存器,硬布线逻辑控制为主,是和采用流水线
CISC的研制周期长
RISC优化编译,有效支持高级语言
大白话就是:
CISC架构,性能好,但是耗电多,电压高。主要用于桌面服务。
RISC架构:耗电少,电压低,但是单核性能比不上CISC架构,主要用于嵌入式开发,或者移动设备开发。
ARM架构,过去称作进阶精简指令集机器(Advanced RISC Machine,更早称作:Acorn RISC Machine),是一个32位精简指令集(RISC)处理器架构
x86或80x86是英代尔Intel首先开发制造的一种微处理器体系结构的泛称。x86架构是重要地可变指令长度的CISC(复杂指令集电脑,Complex Instruction Set Computer)。
MIPS是世界上很流行的一种RISC处理器。MIPS的意思是“无内部互锁流水级的微处理器”(Microprocessor without interlockedpipedstages)
PowerPC 是一种精简指令集(RISC)架构的中央处理器(CPU),其基本的设计源自IBM(国际商用机器公司)的IBMPowerPC 601 微处理器POWER(PerformanceOptimized With Enhanced RISC
Intel 与 AMD是两个公司,amd 与 arm 又是同一个公司(AMD)的两款产品
Intel与AMD共同采用x86架构,都采用CICS指令集,一般用于桌面应用;
而arm 采用 ARM架构,采用RICS指令集,例如家用游戏机、平板、手机等会采用arm CPU;另外苹果公司的M1、M2芯片也是采用ARM架构。
可以说,AMD CPU是 AMD公司为对抗Intel公司的Intel CPU推出的第一代产品;
而 ARM CPU 是AMD公司为了对抗Intel公司的Intel CPU推出的第二代产品,
1 |
|
| 名称 | 谁来清理入栈参数 | 参数压栈顺序 | 函数名转换规则 |
|---|---|---|---|
| __stdcall | 被调用函数在返回前清理入栈参数 | 参数自右向左压栈 | C语言时,_function@number,number为参数的字节数;C++编译时函数名的转换:?function@@YG**@Z或者?function@@YG*XZ;若函数有参数,以@Z结束;若函数无参数,则以Z结束 |
| __cdecl | 调用函数在返回后清理入栈参数 | 参数自右向左压栈 | _function,其中function为函数名;C++编译时函数名的转换:同__stdcall,把YG改为YA |
| __fastcall | 被调用函数在返回前清理入栈参数 | 使用ECX传递第一个参数,EDX传递第二个参数,其余参数自右向左压栈 | C编译时函数名的转换:@function@number;C++编译时函数名的转换:同__stdcall,把YG改为YI |
| __pascal | 被调用函数在返回前清理入栈参数 | 参数自左向右压栈 | 较为复杂,参加pascal文档 |
You are given two eggs, and access to a 100-storey building. Both eggs are identical. The aim is to find out the highest floor from which an egg will not break when dropped out of a window from that floor. If an egg is dropped and does not break, it is undamaged and can be dropped again. However, once an egg is broken, that’s it for that egg.
If an egg breaks when dropped from floor n, then it would also have broken from any floor above that. If an egg survives a fall, then it will survive any fall shorter than that.
The question is: What strategy should you adopt to minimize the number egg drops it takes to find the solution?. (And what is the worst case for the number of drops it will take?)
