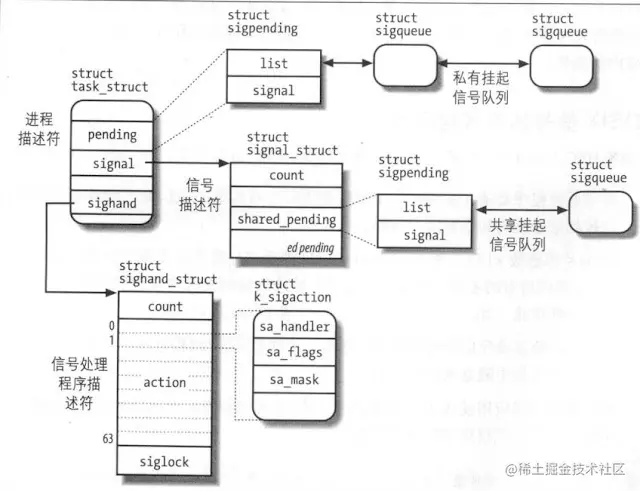
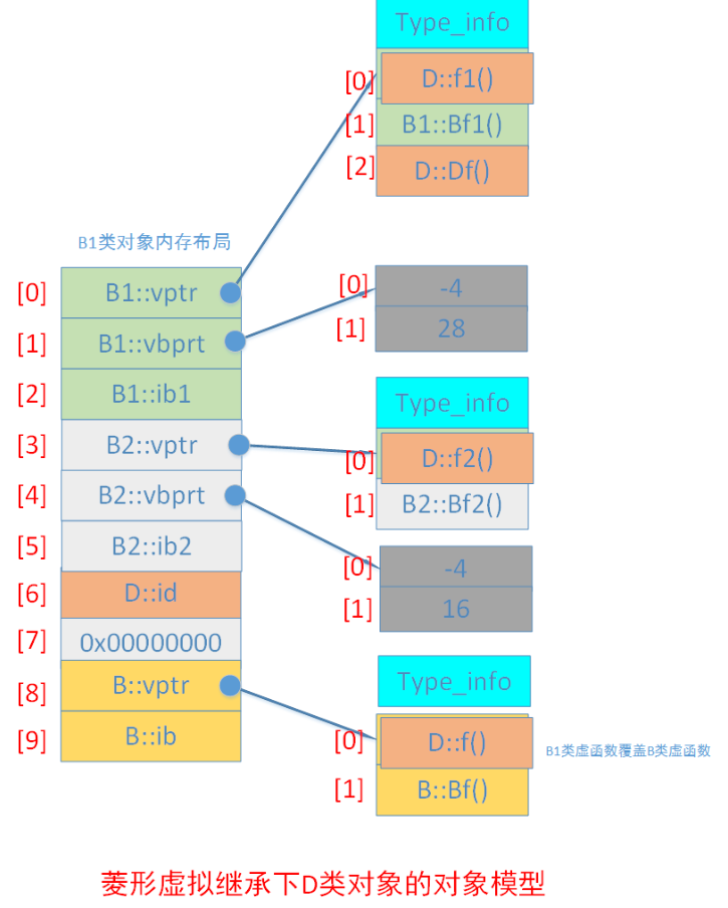
相关技术要点:
- 数据结构/算法优化
- 架构分层
一篇比较好的文章:
https://blog.csdn.net/ArtAndLife/article/details/121001656

正常一个fd会有等待队列,表示有哪一些进程在等待fd可用;
当一个进程在等待一个fd时,内核会把进程结构体从运行队列摘除,放在fd的等待队列上【这样子内核就不会调度到该进程了】
当某个端口有数据可读时,内核会跟进端口查索引表,找到对应的fd
对于select,会频繁的将进程挂在所有FD的等待队列上,然后在select返回的时候,再重新将进程从等待队列中移除,放回到运行队列上。
当进程被唤醒的时候,用户程序也需要遍历fd array,去GET哪些FD可读。
性能极其差!
eventpoll作为一个中间结构,替代进程,挂在对应的等待队列
而调用epoll_wait的进程当被阻塞的时候是挂在在eventpoll的等待队列上。

select低效的另一个原因在于程序不知道哪些socket收到数据,只能一个一个的遍历。如果内核维护一个“就绪列表”,引用收到的数据的socket,就能避免遍历。

当一个FD就绪后,需要做的事
红黑树在epoll中就保存在linux内核中的一块cache,然后通过在这个cache来进行文件描述符的插入删除等操作,由于红黑树的插入删除速度比较良好,查找效率也比较优秀,所以epoll性能提升的很大一个原因就在于此。红黑树只是数据的一个载体:当我们需要频繁的对数据进行插入删除而且还需要保证查找效率的时候,就应该想到使用红黑树。
rdllist
答案:epoll 实例中包含就绪事件的 fd 组成的链表。
rbn
答案:epoll 实例所关心的fd。
使用场景:
epoll 在应对大量网络连接时,只有活跃连接很少的情况下才能表现的性能优异。换句话说,epoll 在处理大量非活跃的连接时性能才会表现的优异。如果15000个 socket 都是活跃的,epoll 和 select 其实差不了太多。
epoll 的 edge-trigger 和 level-trigger 模式处理逻辑差异极小,性能测试结果表明常规应用场景 中二者性能差异可以忽略。
? 使用 edge-trigger 的 user app 比使用 level-trigger 的逻辑复杂,出错概率更高。
? edge-trigger 和 level-trigger 的性能差异主要在于 epoll_wait 系统调用的处理速度,是否是 user app 的性能瓶颈需要视应用场景而定,不可一概而论。
但从 kernel 代码来看,edge-trigger/level-trigger 模式的处理逻辑几乎完全相同,差别仅在于 level-trigger 模式在 event 发生时不会将其从 ready list 中移除,略为增大了 event 处理过程中 kernel space 中记录数据的大小。
[最后看看epoll独有的两种模式LT和ET。无论是LT和ET模式,都适用于以上所说的流程。区别是,LT模式下,只要一个句柄上的事件一次没有处理完,会在以后调用epoll_wait时次次返回这个句柄,而ET模式仅在第一次返回。]
然而,edge-trigger 模式一定要配合 user app 中的 ready list 结构,以便收集已出现 event 的 fd,再通过 round-robin 方式挨个处理,以此避免通信数据量很大时出现忙于处理热点 fd 而导致非热点 fd 饿死的现象。统观 kernel 和 user space,由于 user app 中 ready list 的实现千奇百怪,不一定都经过仔细的推敲优化,因此 edge-trigger 的总内存开销往往还大于 level-trigger 的开销。
一般号称 edge-trigger 模式的优势在于能够减少 epoll 相关系统调用,这话不假,但 user app 里可不是只有 epoll 相关系统调用吧?为了绕过饿死问题,edge-trigger 模式的 user app 要自行进行 read/write 循环处理,这其中增加的系统调用和减少的 epoll 系统调用加起来,有谁能说一定就能明显地快起来呢?
当然操作系统开发人员也会意识到这些缺陷,并且在设计poll接口时解决了大部分问题,因此你会问,还有任何理由使用select吗?为什么不直接淘汰它了?其实还有两个理由使用它:
1.第一个原因是可移植性。select已经存在很长时间了,你可以确定每个支持网络和非阻塞套接字的平台都会支持select,而它可能还不支持poll。另一种选择是你仍然使用poll然后在那些没有poll的平台上使用select来模拟它。
2.第二个原因是select的超时时间理论上可以精确到微秒级别。而poll和epoll的精度只有毫秒级。这对于桌面或者服务器系统来说没有任何区别,因为它们不会运行在纳秒精度的时钟上,但是在某些与硬件交互的实时嵌入式平台,降低控制棒关闭核反应堆.可能是需要的。(这就可以作为一个更加精确的sleep()来用)
什么时候应该选择使用Poll:
跨平台
同一时刻你的应用程序监听的套接字少于1000(这种情况下使用epoll不会得到任何益处)。
您的应用程序需要一次监视超过1000个套接字,但连接非常短暂(这是一个接近的情况,但很可能在这种情况下,您不太可能看到使用epoll的任何好处,因为epoll 的加速将这些新描述符添加到集合中会浪费等待 - 见下文
您的应用程序的设计方式不是在另一个线程正在等待它们更改事件(即您没有使用kqueue或IO完成端口移植应用程序)。
EPoll的缺点:
1.改变监听事件的类型(例如从读事件改为写事件)需要调用epoll_ctl系统调用,而这在poll中只需要在用户空间简单的设置一下对应的掩码。如果需要改变5000个套接字的监听事件类型就需要5000次系统调用和上下文切换(直到2014年epoll_ctl函数仍然不能批量操作,每个描述符只能单独操作),这在poll中只需要循环一次pollfd结构体。
2.每一个被accept()的套接字都需要添加到集合中,在epoll中必须使用epoll_ctl来添加–这就意味着每一个新的连接都需要两次系统调用,而在poll中只需要一次。如果你的服务有非常多的短连接它们都接受或者发送少量数据,epoll所花费的时间可能比poll更长。(解释了上文)
3.epoll是Linux上独有的,虽然其他平台上也有类似的机制但是他们的区别非常大,例如边沿触发这种模式是非常独特的(FreeBSD的kqueue对它的支持非常粗糙)。
什么情况下使用Epoll:
1.你的程序通过多个线程来处理大量的网络连接。如果你的程序只是单线程的那么将会失去epoll的很多优点。并且很有可能不会比poll更好。
2.你需要监听的套接字数量非常大(至少1000);如果监听的套接字数量很少则使用epoll不会有任何性能上的优势甚至可能还不如poll。
3.你的网络连接相对来说都是长连接;就像上面提到的epoll处理短连接的性能还不如poll因为epoll需要额外的系统调用来添加描述符到集合中。
4.你的应用程序依赖于Linux上的其他特性