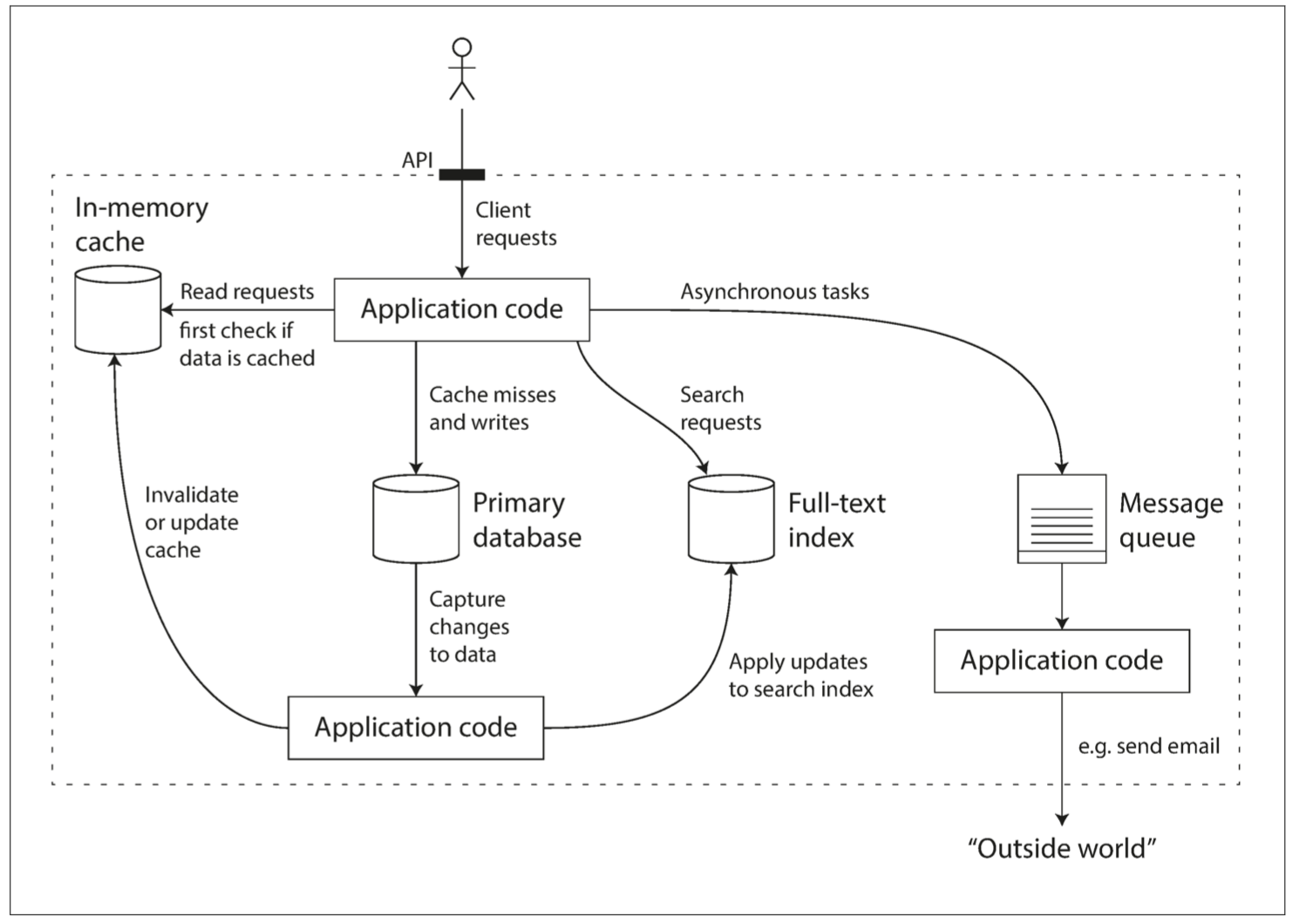
软件设计模式的几种分类
创建型
创建对象时,不再由我们直接实例化对象;而是根据特定场景,由程序来确定创建对象的方式,从而保证更大的性能、更好的架构优势。
创建型模式主要有:
简单工厂模式
工厂方法
意图:定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。
主要解决:主要解决接口选择的问题。
何时使用:我们明确地计划不同条件下创建不同实例时。
如何解决:让其子类实现工厂接口,返回的也是一个抽象的产品。
关键代码:创建过程在其子类执行。
应用实例:
1、您需要一辆汽车,可以直接从工厂里面提货,而不用去管这辆汽车是怎么做出来的,以及这个汽车里面的具体实现。
2、Hibernate 换数据库只需换方言和驱动就可以。
优点:
1、一个调用者想创建一个对象,只要知道其名称就可以了。
2、扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
3、屏蔽产品的具体实现,调用者只关心产品的接口。
缺点:每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
使用场景:
1、日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。
2、数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。
3、设计一个连接服务器的框架,需要三个协议,”POP3”、”IMAP”、”HTTP”,可以把这三个作为产品类,共同实现一个接口。
注意事项:作为一种创建类模式,在任何需要生成复杂对象的地方,都可以使用工厂方法模式。有一点需要注意的地方就是复杂对象适合使用工厂模式,而简单对象,特别是只需要通过 new 就可以完成创建的对象,无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
抽象工厂模式
就是建立一个工厂类,对实现了同一接口的一些类进行实例的创建。简单工厂模式的实质是由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类(这些产品类继承自一个父类或接口)的实例。
意图:提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
主要解决:主要解决接口选择的问题。
何时使用:系统的产品有多于一个的产品族,而系统只消费其中某一族的产品。
如何解决:在一个产品族里面,定义多个产品。
关键代码:在一个工厂里聚合多个同类产品。
应用实例:
优点:当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
缺点:产品族扩展非常困难,要增加一个系列的某一产品,既要在抽象的 Creator 里加代码,又要在具体的里面加代码。
使用场景: 1、QQ 换皮肤,一整套一起换。 2、生成不同操作系统的程序。
注意事项:产品族难扩展,产品等级易扩展。
单例模式
全局资源管理,简化访问。
意图:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
主要解决:一个全局使用的类频繁地创建与销毁。
何时使用:当您想控制实例数目,节省系统资源的时候。
如何解决:判断系统是否已经有这个单例,如果有则返回,如果没有则创建。
关键代码:构造函数是私有的。
应用实例:
1、一个班级只有一个班主任。
2、Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。
3、一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。
优点:
1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
2、避免对资源的多重占用(比如写文件操作)。
缺点:没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
使用场景:
1、要求生产唯一序列号。
2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
注意事项:getInstance() 方法中需要使用同步锁 synchronized (Singleton.class) 防止多线程同时进入造成 instance 被多次实例化。
建造者模式
意图:将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。
主要解决:主要解决在软件系统中,有时候面临着”一个复杂对象”的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定。
何时使用:一些基本部件不会变,而其组合经常变化的时候。
如何解决:将变与不变分离开。
关键代码:建造者:创建和提供实例,导演:管理建造出来的实例的依赖关系。
应用实例:
1、去肯德基,汉堡、可乐、薯条、炸鸡翅等是不变的,而其组合是经常变化的,生成出所谓的”套餐”。
2、JAVA 中的 StringBuilder。
优点: 1、建造者独立,易扩展。 2、便于控制细节风险。
缺点: 1、产品必须有共同点,范围有限制。 2、如内部变化复杂,会有很多的建造类。
使用场景: 1、需要生成的对象具有复杂的内部结构。 2、需要生成的对象内部属性本身相互依赖。
一个类的各个组成部分的具体实现类或者算法经常面临着变化,但是将他们组合在一起的算法却相对稳定。提供一种封装机制 将稳定的组合算法于易变的各个组成部分隔离开来。
注意事项:与工厂模式的区别是:建造者模式更加关注与零件装配的顺序
原型模式
意图:用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
主要解决:在运行期建立和删除原型。
何时使用:
1、当一个系统应该独立于它的产品创建,构成和表示时。
2、当要实例化的类是在运行时刻指定时,例如,通过动态装载。
3、为了避免创建一个与产品类层次平行的工厂类层次时。
4、当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些。
如何解决:利用已有的一个原型对象,快速地生成和原型对象一样的实例。
关键代码:
1、实现克隆操作,在 JAVA 实现 Cloneable 接口,重写 clone(),在 .NET 中可以使用 Object 类的 MemberwiseClone() 方法来实现对象的浅拷贝或通过序列化的方式来实现深拷贝。
2、原型模式同样用于隔离类对象的使用者和具体类型(易变类)之间的耦合关系,它同样要求这些”易变类”拥有稳定的接口。
应用实例: 1、细胞分裂。 2、JAVA 中的 Object clone() 方法。
优点: 1、性能提高。 2、逃避构造函数的约束。
缺点: 1、配备克隆方法需要对类的功能进行通盘考虑,这对于全新的类不是很难,但对于已有的类不一定很容易,特别当一个类引用不支持串行化的间接对象,或者引用含有循环结构的时候。 2、必须实现 Cloneable 接口。
使用场景: 1、资源优化场景。 2、类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等。 3、性能和安全要求的场景。 4、通过 new 产生一个对象需要非常繁琐的数据准备或访问权限,则可以使用原型模式。 5、一个对象多个修改者的场景。 6、一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用。 7、在实际项目中,原型模式很少单独出现,一般是和工厂方法模式一起出现,通过 clone 的方法创建一个对象,然后由工厂方法提供给调用者。原型模式已经与 Java 融为浑然一体,大家可以随手拿来使用。
注意事项:与通过对一个类进行实例化来构造新对象不同的是,原型模式是通过拷贝一个现有对象生成新对象的。浅拷贝实现 Cloneable,重写,深拷贝是通过实现 Serializable 读取二进制流。
结构型
用于帮助将多个对象组织成更大的结构。
结构型模式主要有:
适配器模式adapter
适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能。
意图:将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
主要解决:主要解决在软件系统中,常常要将一些”现存的对象”放到新的环境中,而新环境要求的接口是现对象不能满足的。
何时使用:
1、系统需要使用现有的类,而此类的接口不符合系统的需要。
2、想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作,这些源类不一定有一致的接口。
3、通过接口转换,将一个类插入另一个类系中。(比如老虎和飞禽,现在多了一个飞虎,在不增加实体的需求下,增加一个适配器,在里面包容一个虎对象,实现飞的接口。)
如何解决:继承或依赖(推荐)。
关键代码:适配器继承或依赖已有的对象,实现想要的目标接口。
应用实例:
1、美国电器 110V,中国 220V,就要有一个适配器将 110V 转化为 220V。
2、JAVA JDK 1.1 提供了 Enumeration 接口,而在 1.2 中提供了 Iterator 接口,想要使用 1.2 的 JDK,则要将以前系统的 Enumeration 接口转化为 Iterator 接口,这时就需要适配器模式。
3、在 LINUX 上运行 WINDOWS 程序。 4、JAVA 中的 jdbc。
优点: 1、可以让任何两个没有关联的类一起运行。 2、提高了类的复用。 3、增加了类的透明度。 4、灵活性好。
缺点: 1、过多地使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是 A 接口,其实内部被适配成了 B 接口的实现,一个系统如果太多出现这种情况,无异于一场灾难。因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。 2.由于 JAVA 至多继承一个类,所以至多只能适配一个适配者类,而且目标类必须是抽象类。
使用场景:有动机地修改一个正常运行的系统的接口,这时应该考虑使用适配器模式。
注意事项:适配器不是在详细设计时添加的,而是解决正在服役的项目的问题。
桥接模式bridge
意图:将抽象部分与实现部分分离,使它们都可以独立的变化。
主要解决:在有多种可能会变化的情况下,用继承会造成类爆炸问题,扩展起来不灵活。
何时使用:实现系统可能有多个角度分类,每一种角度都可能变化。
如何解决:把这种多角度分类分离出来,让它们独立变化,减少它们之间耦合。
关键代码:抽象类依赖实现类。
应用实例:
1、猪八戒从天蓬元帅转世投胎到猪,转世投胎的机制将尘世划分为两个等级,即:灵魂和肉体,前者相当于抽象化,后者相当于实现化。生灵通过功能的委派,调用肉体对象的功能,使得生灵可以动态地选择。
2、墙上的开关,可以看到的开关是抽象的,不用管里面具体怎么实现的。
优点:
1、抽象和实现的分离。
2、优秀的扩展能力。
3、实现细节对客户透明。
缺点:桥接模式的引入会增加系统的理解与设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽象进行设计与编程。
使用场景: 1、如果一个系统需要在构件的抽象化角色和具体化角色之间增加更多的灵活性,避免在两个层次之间建立静态的继承联系,通过桥接模式可以使它们在抽象层建立一个关联关系。 2、对于那些不希望使用继承或因为多层次继承导致系统类的个数急剧增加的系统,桥接模式尤为适用。 3、一个类存在两个独立变化的维度,且这两个维度都需要进行扩展。
注意事项:对于两个独立变化的维度,使用桥接模式再适合不过了。
组合器模式component
意图:将对象组合成树形结构以表示”部分-整体”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
主要解决:它在我们树型结构的问题中,模糊了简单元素和复杂元素的概念,客户程序可以像处理简单元素一样来处理复杂元素,从而使得客户程序与复杂元素的内部结构解耦。
何时使用:
1、您想表示对象的部分-整体层次结构(树形结构)。
2、您希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象。
如何解决:树枝和叶子实现统一接口,树枝内部组合该接口。
关键代码:树枝内部组合该接口,并且含有内部属性 List,里面放 Component。
应用实例:
1、算术表达式包括操作数、操作符和另一个操作数,其中,另一个操作数也可以是操作数、操作符和另一个操作数。
2、在 JAVA AWT 和 SWING 中,对于 Button 和 Checkbox 是树叶,Container 是树枝。
优点:
1、高层模块调用简单。 2、节点自由增加。
缺点:在使用组合模式时,其叶子和树枝的声明都是实现类,而不是接口,违反了依赖倒置原则。
使用场景:部分、整体场景,如树形菜单,文件、文件夹的管理。
注意事项:定义时为具体类。
外观门面模式Facade
意图:为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
主要解决:降低访问复杂系统的内部子系统时的复杂度,简化客户端之间的接口。
何时使用: 1、客户端不需要知道系统内部的复杂联系,整个系统只需提供一个”接待员”即可。 2、定义系统的入口。
如何解决:客户端不与系统耦合,外观类与系统耦合。
关键代码:在客户端和复杂系统之间再加一层,这一层将调用顺序、依赖关系等处理好。
应用实例:
1、去医院看病,可能要去挂号、门诊、划价、取药,让患者或患者家属觉得很复杂,如果有提供接待人员,只让接待人员来处理,就很方便。
2、JAVA 的三层开发模式。
优点: 1、减少系统相互依赖。 2、提高灵活性。 3、提高了安全性。
缺点:不符合开闭原则,如果要改东西很麻烦,继承重写都不合适。
使用场景:
1、为复杂的模块或子系统提供外界访问的模块。
2、子系统相对独立。 3、预防低水平人员带来的风险。
注意事项:在层次化结构中,可以使用外观模式定义系统中每一层的入口。
亨元模式flyweight
意图:运用共享技术有效地支持大量细粒度的对象。
主要解决:在有大量对象时,有可能会造成内存溢出,我们把其中共同的部分抽象出来,如果有相同的业务请求,直接返回在内存中已有的对象,避免重新创建。
何时使用:
1、系统中有大量对象。
2、这些对象消耗大量内存。
3、这些对象的状态大部分可以外部化。
4、这些对象可以按照内蕴状态分为很多组,当把外蕴对象从对象中剔除出来时,每一组对象都可以用一个对象来代替。
5、系统不依赖于这些对象身份,这些对象是不可分辨的。
如何解决:用唯一标识码判断,如果在内存中有,则返回这个唯一标识码所标识的对象。
关键代码:用 HashMap 存储这些对象。
应用实例:
1、JAVA 中的 String,如果有则返回,如果没有则创建一个字符串保存在字符串缓存池里面。
2、数据库的数据池。
优点:大大减少对象的创建,降低系统的内存,使效率提高。
缺点:提高了系统的复杂度,需要分离出外部状态和内部状态,而且外部状态具有固有化的性质,不应该随着内部状态的变化而变化,否则会造成系统的混乱。
使用场景: 1、系统有大量相似对象。 2、需要缓冲池的场景。
注意事项: 1、注意划分外部状态和内部状态,否则可能会引起线程安全问题。 2、这些类必须有一个工厂对象加以控制。
装饰器模式decorator
对已有的业务逻辑进一步的封装,使其增加额外的功能,如java中的IO流就使用了装饰者模式,用户在使用的时候,可以任意组装,达到自己想要的效果。
代理模式proxy
代理模式是给某一个对象提供一个代理,并由代理对象控制对原对象的引用。
优点:代理模式能够协调调用者和被调用者,在一定程度上降低了系统的耦合度;可以灵活地隐藏被代理对象的部分功能和服务,也增加额外的功能和服务。
缺点:
由于使用了代理模式,因此程序的性能没有直接调用性能高;使用代理模式提高了代码的复杂度。
举一个生活中的例子:比如买飞机票,由于离飞机场太远,直接去飞机场买票不太现实,这个时候我们就可以上携程 App 上购买飞机票,这个时候携程 App 就相当于是飞机票的代理商。
行为型
用于帮助系统间各对象的通信,以及如何控制复杂系统中流程。
行为型模式主要有:
解释器模式
用的比较少,可能出现的地方:语法解析
中介者模式
作用:
通过使用一个中间对象来进行消息分发以及减少类之间的直接依赖。
本质:
ComponentA,ComponentB,ComponentC 都拥有一个Mediator(拥有一个方法notify)
当某一个Component执行某一个操作的时候, 除了做完自己的事情,还需要Mediator::Notify
Mediator有一个具体的子类叫:ConcreteMediator,他拥有所有的Component,并overwrite了Notify接口
命令模式command
命令模式:将一个请求封装为一个对象,从而使你可以用不同的请求对客户进行参数化,对请求排队和记录请求日志,以及支持可撤销的操作。
应用场景:将命令者与执行者完全解耦。
Java中的Runnable就是命令模式
迭代器模式
STL::iterator
备忘录模式
Originator 发起者;
CareTaker 备忘录管理者,管理所有的备忘录快照
Memoto 备忘录,有getState, setState两个方法
一个游戏,玩一会儿,自动存档,再玩一会,自动存档。就可以考虑用备忘录模式
观察者模式
发布订阅模式
对象间一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。Android中的各种Listener就使用到了这一设计模式,只要用户对手机进行操作,对应的listener就会被通知,并作出响应的处理。
状态模式state
状态模式:允许对象在其内部状态改变时改变他的行为。对象看起来似乎改变了他的类。
应用场景:一个对象的内部状态改变时,他的行为剧烈的变化。
context 使用 State
concreteStateA,B,C继承自State
concreteStateA 可以在实现时切换状态到B
模板模式
模板方法模式是指定义一个模板结构,将具体内容延迟到子类去实现。
让子类可以重写方法的一部分,而不是整个重写,你可以控制子类需要重写那些操作。
做一件事情需要1,2,3三步,父类提供了基本实现,子类也可以选择overwrite。
策略模式
答:策略模式是指定义一系列算法,将每个算法都封装起来,并且使他们之间可以相互替换。
优点:遵循了开闭原则,扩展性良好。
缺点:随着策略的增加,对外暴露越来越多。
策略模式则是以接口形式提供抽象接口。由具体实现类提供不同算法。
策略模式一般由3部分组成
- 一个Context持有所有策略实现类引用,提供给客户端运行
- 一个策略接口提供
- 具体的策略实现类
通过上面可以看到,策略模式和模板模式有一个最重要的区别,即模板模式一般只针对一套算法,注重对同一个算法的不同细节进行抽象提供不同的实现。而策略模式注重多套算法多套实现,在算法中间不应该有交集,因此算法和算法只间一般不会有冗余代码!因为不同算法之间的实现一般不同很相近。
因此我们可以看到,策略模式的关注点更广,模板模式的关注点更深。而且两种模式可以一起使用,即具体某个策略下可以通过模板减少不同步骤的冗余代码。
例如:限流是服务器要实现的功能,但是实现策略有基于滑动窗口的限流策略、基于令牌桶的限流策略等。
访问者模式
用途:文件遍历
java.nio.file.FileVisitor接口
类功能:一个用于访问文件的接口。这一接口的实现类通过Files.walkFileTree方法实现对文件树中每一个文件的访问。
public static Path walkFileTree(Path start,Set options,
int maxDepth,FileVisitor< super Path> visitor) ,这一方法中回调了visitor的方法。
方法实现上:访问者对每一个被访问者都有一个实现方法。每一个被访问者都有一个通用方法,输入参数为访问者,此方法用于调用访问者的方法。
责任链
webserver的filter
通过把请求从一个对象传递到链条中下一个对象的方式来解除对象之间的耦合,直到请求被处理完毕。链中的对象是同一接口或抽象类的不同实现。
参考:
https://blog.csdn.net/sinat_34166518/article/details/89206059