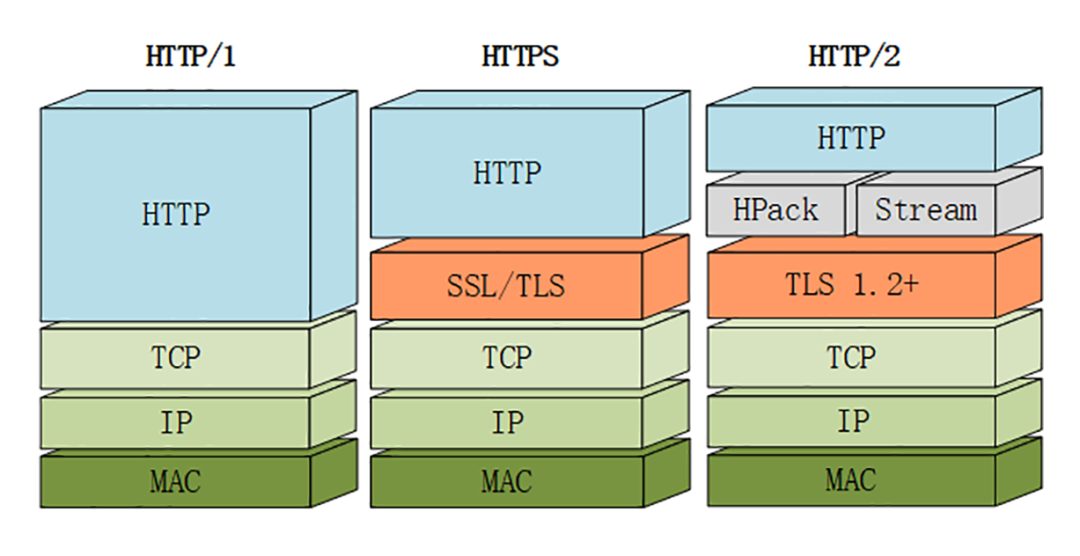
HTTP1.0
301: 永久重定向
302: 临时重定向
!默认关闭!
在HTTP 1.0中,服务器始终在发送响应后关闭连接, 除非客户端发送了Connection: keep-alive请求标头,并且服务器发送了一个Connection: keep-alive响应标头。 如果不存在这样的响应报头,则客户端在收到响应后必须关闭连接的结束。
!默认打开!
在HTTP 1.1中,服务器在发送响应之后不关闭连接, 除非客户端发送了Connection: close请求标头,或者服务器发送了Connection: close响应标头。 如果存在这样的响应头,则客户端在收到响应后必须关闭连接的结束。
HTTPS
可以参考:https://blog.csdn.net/xiaoming100001/article/details/81109617
对称加密与非对称加密相结合
通信内容,通过对称加密算法来加解密;其中有一个重要的东西叫:密钥
密钥是通过非对称加密算法来加密传输,客户端使用服务器的public key来加密,服务端通过自己的private key来解密。
服务器的public key,浏览器如何得知呢? 通过SSL证书。
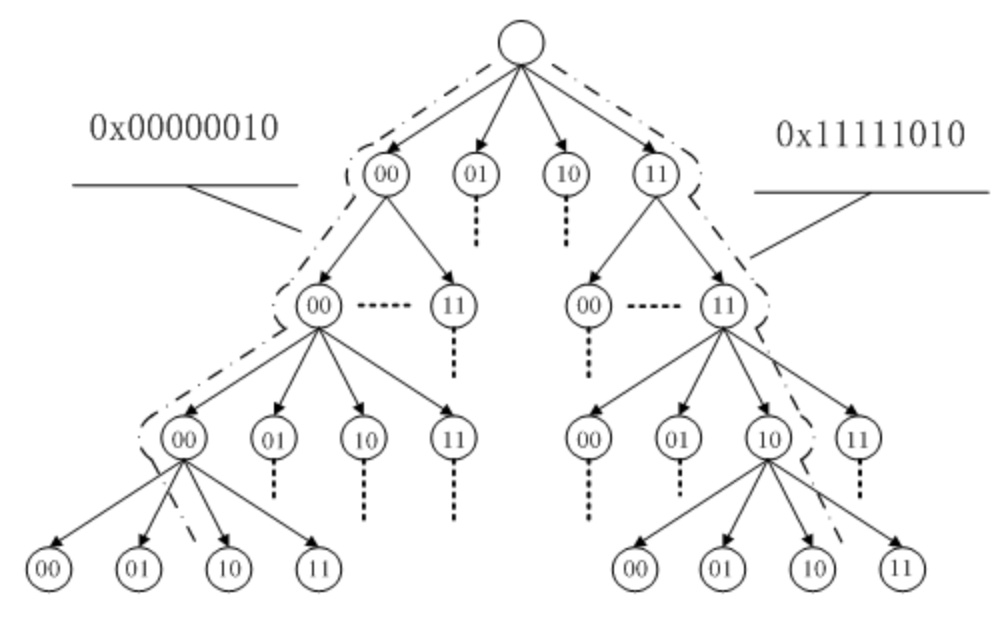
SSL证书组织是一个树形组织,最上面的几层是hardcode在系统中的。
当需要验证证书有效性时,浏览器会通过根认证组织逐层认证!
证书的制造过程:
(1)证书颁发由CA进行
(2)证书会对证书明文(网站信息)进行hash
(3)然后把hash用自己的私钥进行加密,得到数字签名
浏览器如何得到证书,如何如何验证证书?
(1)当访问网站S的时候,S会把自己的证书发回给浏览器
(2)浏览器看看证书的颁发者是否可信(如果不可信,需要递归进行,一直到Global CA,自验证!)
(3)如果可信的话,则讲证书明文信息进行hash,得到H1;然后用CA公钥对证书中的数字签名进行解密,得到H2;比对H1,H2是否一致;
(4)如果不一致,则说明证书被篡改;
(5)如果证书合法,一般情况下还校验证书明文中的域名与目标域名是否一致【这个检查是为了防止整个证书被某些网站调包!】
(5)至此,证书ok, 取出其中网站S的公钥用作后续通信的基础。
可以参考:https://www.cnblogs.com/hh9515/p/14885078.html
HTTP2.0
服务器推送、头信息压缩、等
二进制分帧
先来理解几个概念:
帧:HTTP/2 数据通信的最小单位消息:指 HTTP/2 中逻辑上的 HTTP 消息。例如请求和响应等,消息由一个或多个帧组成。
流:存在于连接中的一个虚拟通道。流可以承载双向消息,每个流都有一个唯一的整数ID。
HTTP/2 采用二进制格式传输数据,而非 HTTP 1.x 的文本格式,二进制协议解析起来更高效。 HTTP / 1 的请求和响应报文,都是由起始行,首部和实体正文(可选)组成,各部分之间以文本换行符分隔。HTTP/2 将请求和响应数据分割为更小的帧,并且它们采用二进制编码。
HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装。
多路复用
在 HTTP/2 中,有了二进制分帧之后,HTTP /2 不再依赖 TCP 链接去实现多流并行了,在 HTTP/2中:
同域名下所有通信都在单个连接上完成。
单个连接可以承载任意数量的双向数据流。
数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装。
服务器推送
服务端可以在发送页面HTML时主动推送其它资源,而不用等到浏览器解析到相应位置,发起请求再响应。例如服务端可以主动把JS和CSS文件推送给客户端,而不需要客户端解析HTML时再发送这些请求。
服务端可以主动推送,客户端也有权利选择是否接收。如果服务端推送的资源已经被浏览器缓存过,浏览器可以通过发送RST_STREAM帧来拒收。主动推送也遵守同源策略,服务器不会随便推送第三方资源给客户端。
头部压缩
HTTP 1.1请求的大小变得越来越大,有时甚至会大于TCP窗口的初始大小,因为它们需要等待带着ACK的响应回来以后才能继续被发送。HTTP/2对消息头采用HPACK(专为http/2头部设计的压缩格式)进行压缩传输,能够节省消息头占用的网络的流量。而HTTP/1.x每次请求,都会携带大量冗余头信息,浪费了很多带宽资源。
为了减少这块的资源消耗并提升性能, HTTP/2对这些首部采取了压缩策略:
HTTP/2在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送;
首部表在HTTP/2的连接存续期内始终存在,由客户端和服务器共同渐进地更新;
每个新的首部键-值对要么被追加到当前表的末尾,要么替换表中之前的值。
HTTP3.0

QUIC(Quick UDP Internet Connections)基于 UDP 实现,是 HTTP/3 中的底层支撑协议,该协议基于 UDP,又取了 TCP 中的精华,实现了即快又可靠的协议
参考:https://blog.51cto.com/u_6315133/3122045