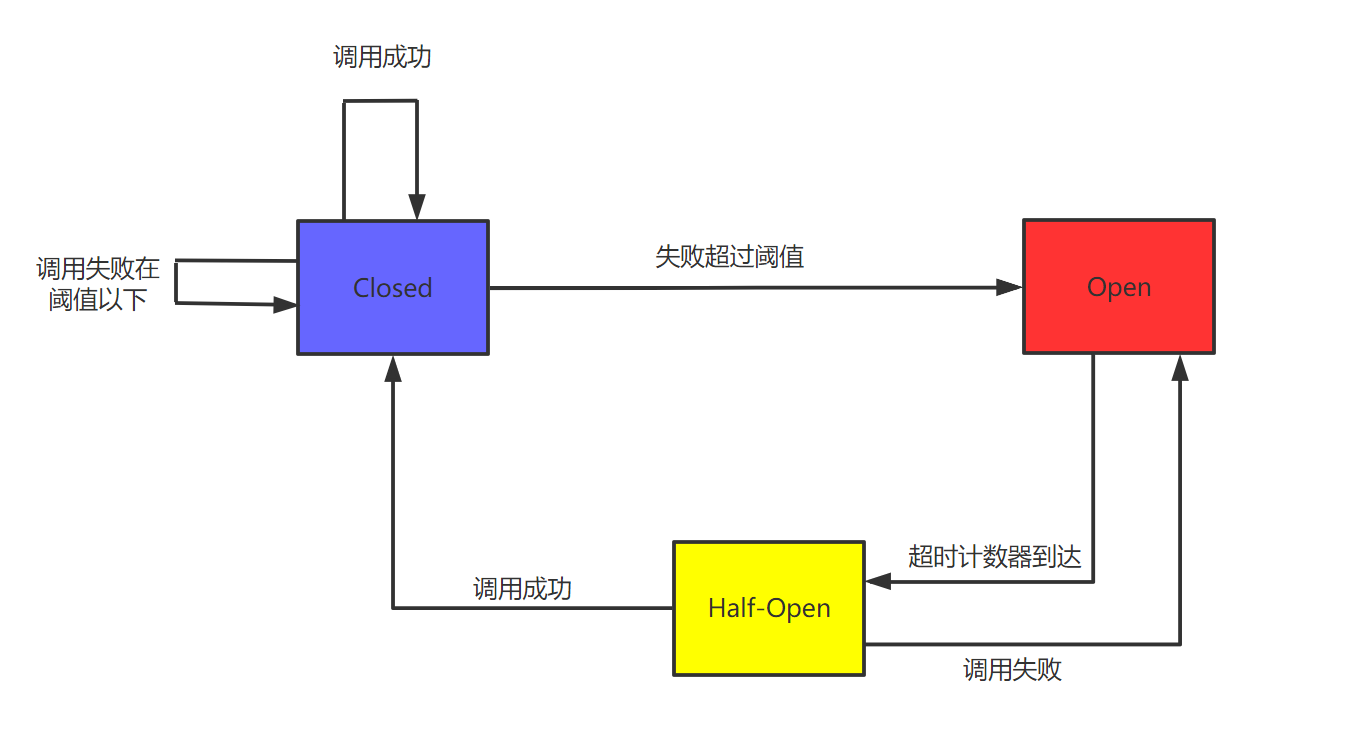
服务的处理能力是有客观上限的。当请求速度超过服务的处理速度时,服务就会过载。
如果服务持续过载,会导致越来越多的请求积压,最终所有的请求都必须等待较长时间才能被处理,从而使整个服务处于瘫痪状态。
与之相对的,如果直接拒绝掉一部分请求,反而能够让服务能够”及时”处理更多的请求。 我们称这种做法为限流。限流是过载保护的手段之一,目的在于保护系统不被超过服务吞吐能力的流量(或突发)打死。
常见的限流手段有固定窗口、滑动窗口、令牌桶、漏桶、BBR、brpc自适应限流等。
下面挨个介绍每一种限流算法的原理以及优缺点。
传统的基于配置的单机限流算法
第一,固定窗口
原理:维护一个窗口的两个信息:窗口开始时间、经过窗口的请求数。如果窗口内超出限制数则拒绝。如果已经进入新的窗口,则reset计数。
不足:存在临界点(窗口reset前后的瞬时)的qps会飙高,从而打死系统。
第二,滑动窗口
原理:将总的时间窗口划分为N个小格,并单独维护每一个小格的计数。通过这种方式,可以把过去一段时间内的计数信息也用上,从而让限流的统计更精确一些。
不足:窗口不可能无限划分
第三,漏桶
原理:漏桶具有固定容量,出水速率是固定常量(流出请求)如果桶是空的,则不需流出水滴。可以以任意速率流入水滴到漏桶(流入请求)如果流入水滴超出了桶的容量,则流入的水滴溢出(新请求被拒绝)
不足:无法应对突发流量

第四,令牌桶
原理:假如用户配置的平均发送速率为r,则每隔1/r秒一个令牌被加入到桶中。假设桶最多可以存发b个令牌。如果令牌到达时令牌桶已经满了,那么这个令牌会被丢弃。当一个n个字节的数据包到达时,就从令牌桶中删除n个令牌,并且数据包被发送到网络。如果令牌桶中少于n个令牌,那么不会删除令牌,并且认为这个数据包在流量限制之外。
算法允许最长b个字节的突发,但从长期运行结果看,数据包的速率被限制成常量r。

自适应限流
上面的几种算法,一定程度上确实能够保护系统不被拖垮, 但不管漏斗桶还是令牌桶, 其防护思路都是设定一个指标, 当超过该指标后就阻止或减少流量的继续进入,当系统负载降低到某一水平后则恢复流量的进入。但其通常都是被动的,其实际效果取决于限流阈值设置是否合理,但往往设置合理不是一件容易的事情。具体有如下几个弊端:
- 集群增加机器或者减少机器限流阈值是否要重新设置?
- 设置限流阈值的依据是什么?
- 人力运维成本是否过高?
- 只针对局部服务端的限流,无法掌控全局资源,
- 当调用方反馈限流错误时, 这个时候重新设置限流, 其实流量高峰已经过了。重新评估限流是否有意义?
第五,B站BBR限流

底层原理:并发 = qps * latency
自适应限流能动态调整服务的最大并发,在保证服务不过载的前提下,让服务尽可能多的处理请求。
具体逻辑:如果cpu > 800 && inflight > rt * max_qps,则启用限流
为什么要用 CPU\IOPS 作为启发值呢?
因为自适应限流与 TCP 拥塞控制还存在不同之处,TCP 中客户端可以控制发送率,从而探测到 maxPass,但是 RPC 线上无法控制流量的速率,所以必须以 CPU 作为标准,当 CPU 快满载的时候再开启,这时我们认为之前探测到的 maxPass 已经接近了系统的瓶颈,乘以 minRtt 就可以得到 InFlight
第六,BRPC自适应限流
- peek_qps 峰值qps
- nodelay_latency 系统无负载或者低负载的响应时间,理论值无法计算
- Min_latency 用来替代nodelay_latency
- max_cocurrent = max_qps * ((2+alpha) * min_latency - latency)
名词及解释
concurrency(并发度): 同时处理的请求数,又被称为“并发度”。
max_concurrency:
设置的最大并发度。超过并发的请求会被拒绝(返回ELIMIT错误),在集群层面,client应重试到另一台server上去。
best_max_concurrency:
并发的物理含义是任务处理槽位,天然存在上限,这个上限就是best_max_concurrency,也就是最佳的最大并发度,一般推荐设置最大并发为该值,若max_concurrency设置的过大,则concurrency可能大于best_max_concurrency,任务将无法被及时处理而暂存在各种队列中排队,系统也会进入拥塞状态。若max_concurrency设置的过小,则concurrency总是会小于best_max_concurrency,限制系统达到本可以达到的更高吞吐。
noload_latency:
单纯处理任务的延时,不包括排队时间。另一种解释是低负载的延时。由于正确处理任务得经历必要的环节,其中会耗费cpu或等待下游返回,noload_latency是一个服务固有的属性,但可能随时间逐渐改变(由于内存碎片,压力变化,业务数据变化等因素)。
min_latency:
实际测定的latency中的较小值的ema,当concurrency不大于best_max_concurrency时,min_latency和noload_latency接近(可能轻微上升)。
peak_qps: 服务处理qps的上限。注意是处理或回复的qps而不是接收的qps。值取决于best_max_concurrency /
noload_latency,这两个量都是服务的固有属性,故peak_qps也是服务的固有属性,和拥塞状况无关,但可能随时间逐渐改变。
max_qps: 实际测定的qps中的较大值。由于qps具有上限,max_qps总是会小于peak_qps,不论拥塞与否。
- Little’s Law
在服务处于稳定状态时: concurrency = latency * qps。 这是自适应限流的理论基础。
服务的noload_latency并非是一成不变的,自适应限流必须能够正确的探测noload_latency的变化。当noload_latency下降时,是很容感知到的,因为这个时候latency也会下降。难点在于当latency上涨时,需要能够正确的辨别到底是服务过载了,还是noload_latency上涨了。
参考:
https://blog.csdn.net/qq_42936727/article/details/134548409
参考: